The one robotics decision that will come back to haunt you
Most robotics teams treat data storage as an afterthought. By the time it becomes a problem, the damage is already done, corrupted formats, lost recordings, months of engineer time poured into infrastructure that should never have been built in-house. Here's what we learned the hard way.
You know that feeling when you’re standing in IKEA, you’ve just picked up a KALLAX shelf, and you’re absolutely convinced you don’t need to read the instructions? It’s just a shelf. You’ve built things before. How hard can it be ?!? Three hours later you’re surrounded by wooden panels, you have four screws left over, and one side is slightly tilted in a way that will bother you forever but not quite enough to take it apart and start over.
Building your own robotics data pipeline feels exactly like that. Except the leftover screws are corrupted sensor recordings, and slightly tilted means you’ve lost months of irreplaceable data.
Every robotics team I’ve talked to has gone through some version of the same story. You start the project, you have a manageable amount of data, you write a quick hack, it works, and you move on. There are harder problems to solve. The robot doesn’t walk yet. The perception stack is a mess. Nobody has time to overthink a data pipeline.
So you don’t. And for a while, that’s completely fine.
The problem is that for a while ends, and it ends faster than you expect. Robotics data doesn’t grow at a steady pace, it compounds. More sensors, higher frequency, new modalities you didn’t plan for. The system that handled a few hundred gigabytes starts groaning at a few terabytes, and by the time you notice, you’re already in trouble.
I know this because I lived it. And I’ve watched it happen more than once across my years in this industry, each time in a way that was genuinely painful to see.
The data you throw away is the data you can never get back
This is the part that still bothers us.
In over a decade working in robotics and autonomous driving, I’ve seen teams collecting data at serious scale, fleet of robots, running every day, generating hours of multi-sensor recordings. The kind of data that is expensive and slow to collect, and that you really only get by having robots out in the real world doing real things.
There was no data management strategy. Not a bad one, just none. Data was accumulating across drives and servers with loose organization and no clear ownership. Nobody had really sat down and asked what would happen when they needed to use it for something, for training a model, for reproducing a failure, for anything beyond the immediate operational need.
When the team eventually tried to go back and use it, a huge portion was just gone in practice. Unreadable formats. Missing calibration metadata. Parsers that no longer worked for files written six months earlier. Some of it was literally deleted because nobody knew if it was still needed. Terabytes of irreplaceable real-world data, thrown away. Not because of a dramatic failure, just because nobody had thought seriously about managing it.

That’s the thing about this mistake. It doesn’t announce itself. You don’t wake up one day and decide to throw away your data. It just slowly becomes unusable while you’re focused on everything else. Like that KALLAX shelf you never quite fixed, except the consequences are a lot worse than a slightly wonky bookcase.
Why the simple pipeline always feels like enough
We get why teams build their own. In the beginning it genuinely is enough, and there’s a natural instinct to avoid dependencies and keep things simple. Writing a quick pipeline feels like the right call when you’re moving fast and the data problem isn’t urgent yet.
The issue is that the pipeline you write at month one is almost never the right tool at month twelve; and the gap between those two things is harder to bridge than it looks.
For one thing, storage format is a real design problem. You’re constantly balancing footprint against latency, and what works well for streaming writes from sensors is usually bad for the random access you need when training models. We optimized for the write side early on, and then hit a wall when we tried to actually use the data for ML.
Concurrent writes are another thing that’s easy to underestimate. When you have many sensors and nodes writing at the same time, making that actually correct, no data corruption, no race conditions under load, is genuinely hard. Our early pipelines would quietly fail under pressure. We didn’t catch it until throughput became a real bottleneck and we went digging.
And then there’s the broader point that save data for inspection and for training are different problems. The access patterns don’t overlap neatly. Trying to serve both with a single homegrown tool almost always means compromising on both.
What it actually costs
Here’s the honest version of the cost calculation. If you want to do this properly, you need to invest a lot of time on it. You’re designing a data platform. A stable format, a correct concurrency model, indexing, retrieval tooling, and a migration strategy for when any of those decisions need to change down the line.
That’s a significant engineering investment. And it’s not a one-time thing, because the problems evolve as you scale. Across multiple projects, we spent a lot of time solving these problems before we finally decided to just build Mosaico and stop reinventing it. The time wasn’t entirely wasted, we learned a lot about what the right decisions look like. But we would have shipped faster if we hadn’t had to figure all of that out from scratch.
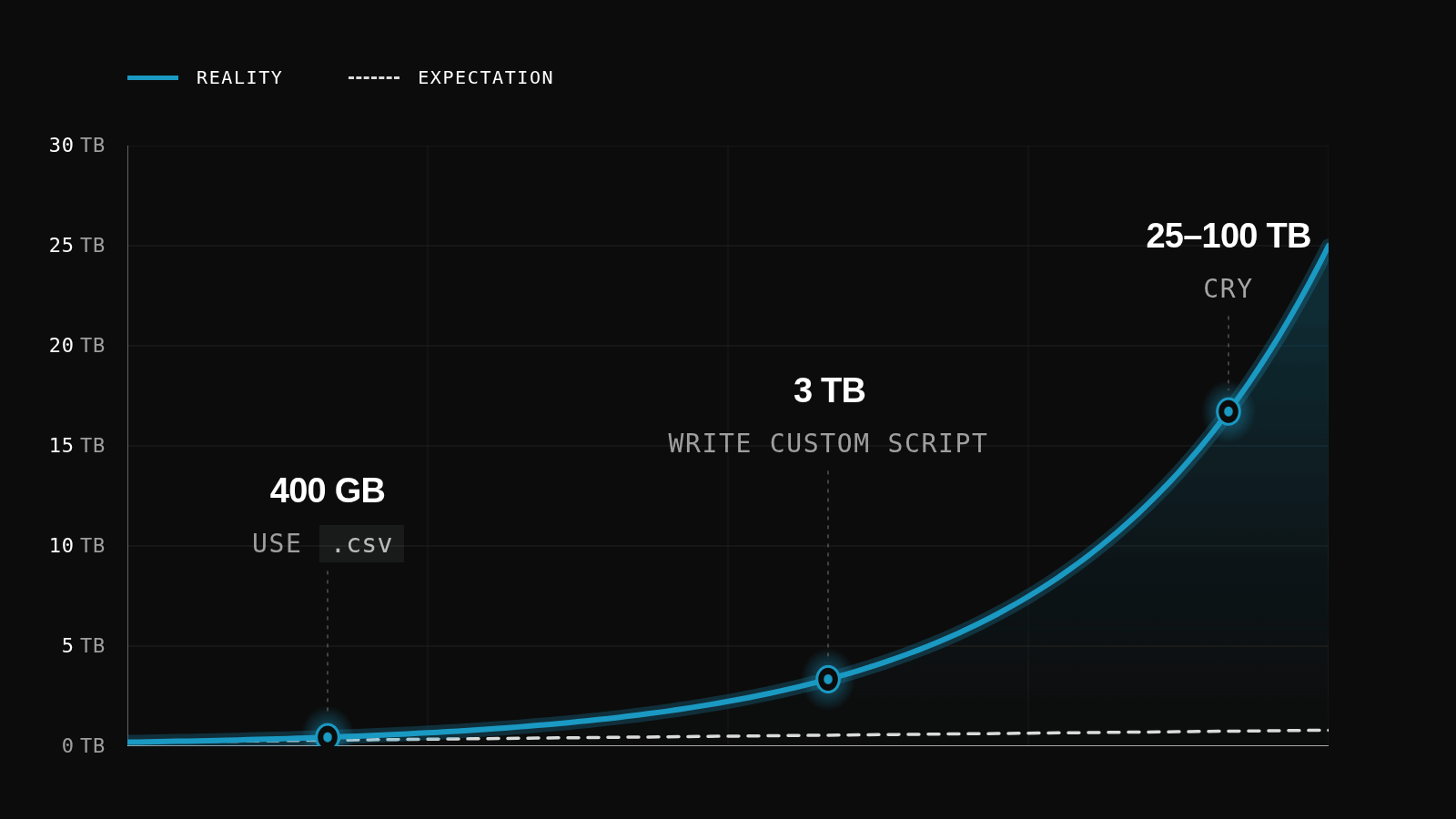
For a small team, every engineer hour spent on storage infrastructure is an hour not spent on the actual robot. That tradeoff is worth taking seriously earlier than most teams do.
On building for your specific stack
The other argument we hear for going in-house is that the pipeline is too custom or proprietary to use anything external. We’ve made that argument ourselves. It’s usually not as true as it feels.
Mosaico is middleware agnostic because we knew this would come up, and because we’d been on the other side of it. It’s designed to fit into your existing pipeline rather than ask you to restructure around it.
We built Mosaico because we were tired of solving the same problem from scratch on every new project. It’s open source because we didn’t think it was right to put a paywall on something this fundamental. Data management isn’t a premium feature of robotics development, it’s the foundation, and it felt wrong to have teams lose months of work, or entire datasets, just because they couldn’t justify a license fee at an early stage.
If none of this applies to you and you have a data strategy you’re happy with, great. But if you’re reading this and some of it sounds familiar, it might be worth taking an afternoon to think seriously about where your data ends up and whether you’ll actually be able to use it a year from now.
Ready to tame
your data chaos?
Join disruptive companies and robotics leaders.
Start building with Mosaico in minutes.
Open source · Deploy in< 5 min